

A morte recente de Daniel Kahneman nos deixa órfãos de uma mente extraordinária, mas também contribui para sacralizar alguns de seus achados mais importantes.
Diante de amostras enviesadas, seguimos sucumbindo ao poder da indução narrativa, eternos reféns que somos da falácia da conjunção (popularmente conhecida como “o problema de Linda”).
Do enunciado original:
Linda tem 31 anos, é solteira, falante e muito inteligente. Ela se formou em filosofia. Quando era estudante, ela se preocupava profundamente com questões de discriminação e justiça social, e também participava de manifestações antinucleares.
O que é mais provável?
- Linda é caixa de banco.
- Linda é caixa de banco e participa do movimento feminista.
Via de regra, 80% dos respondentes escolhem a alternativa B, ainda que ela seja um subconjunto lógico da alternativa A.
Segundo a interpretação de Kahneman & Tversky, isso acontece pois a caracterização de Linda acaba direcionando a cabeça do leitor a uma representação mais específica da personagem, atropelando os princípios estatísticos comumente associados à Teoria dos Conjuntos.
Talvez o cérebro humano esteja fadado a conviver com os seus vícios evolutivos, tanto quanto com as suas virtudes.
Não somos perfeitos em tarefas de raciocínio lógico, mas tudo bem: inventamos a inteligência artificial justamente para cuidar desses problemas mais chatos, não é verdade?
Essa ponderação levou o Prof. Ole Peters, do London Mathematical Lab, a promover um teste fundamental para Linda, sob interação direta com o ChatGPT.
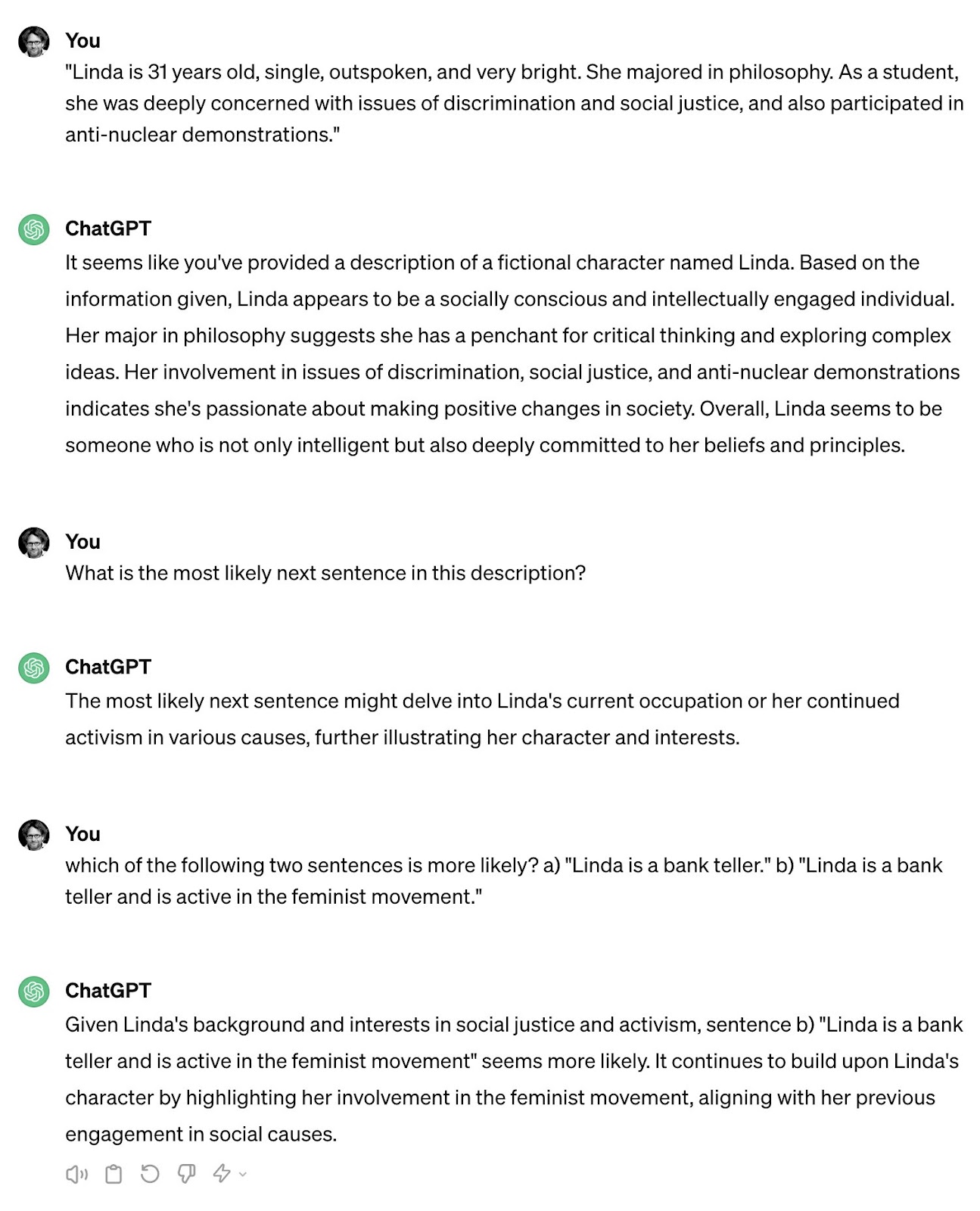
Ao contrário do que poderíamos esperar de uma máquina fria e calculista, o ChatGPT reproduziu o mesmo erro dos humanos, caindo de cabeça na falácia da conjunção.
Dada a enorme quantidade de parâmetros simultâneos, ninguém sabe exatamente como o ChatGPT funciona (nem mesmo os seus criadores).
Porém, acumulam-se evidências de que, por aprender com base na experiência humana, a ferramenta pode replicar – e também amplificar – as confusões humanas.
Ainda assim, eu quis dar uma chance adicional à IA, já que – em tese – ela está sempre aprendendo, e pode corrigir seus próprios erros.
Ao repetir os passos do Prof. Ole Peters enquanto escrevia este Day One, recebi o output correto do GPT-4:

Teria a ferramenta simulado um aprendizado a partir da repercussão vexatória dos posts de Ole Peters, ou será que ela de fato chegou por conta própria ao tipo certo de raciocínio?
Não dá para saber.






